정렬
참고 블로그
https://coding-factory.tistory.com/615
[Algorithm] 각 정렬의 특징 및 장단점 & 시간복잡도
정렬 별 특징 선택정렬 (Selection Sort) 선택정렬은 앞에서부터 차례대로 정렬하는 방법입니다. 먼저 주어진 리스트 중에 최소값을 찾고 그 값을 맨 앞에 위치한 값과 교체하는 방식으로 진행하는
coding-factory.tistory.com
Tip
두 변수의 값을 교체하는 방법
a, b = b, a
- 버블정렬 예시
input = [4, 6, 2, 9, 1]
def bubble_sort(array):
n = len(array)
for i in range(n):
for j in range(n - i - 1):
if array[j] > array[j + 1]:
array[j], array[j + 1] = array[j + 1], array[j]
return array
bubble_sort(input)
print(input)
print("정답 = [1, 2, 4, 6, 9] / 현재 풀이 값 = ",bubble_sort([4, 6, 2, 9, 1]))
print("정답 = [-1, 3, 9, 17] / 현재 풀이 값 = ",bubble_sort([3,-1,17,9]))
print("정답 = [-3, 32, 44, 56, 100] / 현재 풀이 값 = ",bubble_sort([100,56,-3,32,44]))
- 선택정렬 예시
input = [4, 6, 2, 9, 1]
def selection_sort(array):
n = len(array)
for i in range(n - 1):
min_index = i
for j in range(n - i):
if array[i + j] < array[min_index]:
min_index = i + j
array[i], array[min_index] = array[min_index], array[i]
return array
selection_sort(input)
print(input)
print("정답 = [1, 2, 4, 6, 9] / 현재 풀이 값 = ",selection_sort([4, 6, 2, 9, 1]))
print("정답 = [-1, 3, 9, 17] / 현재 풀이 값 = ",selection_sort([3,-1,17,9]))
print("정답 = [-3, 32, 44, 56, 100] / 현재 풀이 값 = ",selection_sort([100,56,-3,32,44]))
- 선택정렬 예시
input = [4, 6, 2, 9, 1]
def insertion_sort(array):
n = len(array)
for i in range(1, n):
for j in range(i):
if array[i - j - 1] > array[i - j]:
array[i - j - 1], array[i - j] = array[i - j], array[i - j - 1]
else:
break
return array
insertion_sort(input)
print(input)
print("정답 = [4, 5, 7, 7, 8] / 현재 풀이 값 = ",insertion_sort([5,8,4,7,7]))
print("정답 = [-1, 3, 9, 17] / 현재 풀이 값 = ",insertion_sort([3,-1,17,9]))
print("정답 = [-3, 32, 44, 56, 100] / 현재 풀이 값 = ",insertion_sort([100,56,-3,32,44]))
- 병합정렬 예시
array = [5, 3, 2, 1, 6, 8, 7, 4]
def merge_sort(array):
if len(array) <= 1:
return array
mid = len(array) // 2
left_array = array[:mid]
right_array = array[mid:]
print(array)
print('left_arary', left_array)
print('right_arary', right_array)
return merge(merge_sort(left_array), merge_sort(right_array))
def merge(array1, array2):
result = []
array1_index = 0
array2_index = 0
while array1_index < len(array1) and array2_index < len(array2):
if array1[array1_index] < array2[array2_index]:
result.append(array1[array1_index])
array1_index += 1
else:
result.append(array2[array2_index])
array2_index += 1
if array1_index == len(array1):
while array2_index < len(array2):
result.append(array2[array2_index])
array2_index += 1
if array2_index == len(array2):
while array1_index < len(array1):
result.append(array1[array1_index])
array1_index += 1
return result
print(merge_sort(array))
# 출력된 값을 보면 다음과 같습니다!
# [5, 3, 2, 1, 6, 8, 7, 4] 맨 처음 array 이고,
# left_arary [5, 3, 2, 1] 이를 반으로 자른 left_array
# right_arary [6, 8, 7, 4] 반으로 자른 나머지가 right_array 입니다!
# [5, 3, 2, 1] 그 다음 merge_sort 함수에는 left_array 가 array 가 되었습니다!
# left_arary [5, 3] 그리고 그 array를 반으로 자르고,
# right_arary [2, 1] 나머지를 또 right_array 에 넣은 뒤 반복합니다.
# [5, 3]
# left_arary [5]
# right_arary [3]
# [2, 1]
# left_arary [2]
# right_arary [1]
# [6, 8, 7, 4]
# left_arary [6, 8]
# right_arary [7, 4]
# [6, 8]
# left_arary [6]
# right_arary [8]
# [7, 4]
# left_arary [7]
# right_arary [4]
print("정답 = [-7, -1, 5, 6, 9, 10, 11, 40] / 현재 풀이 값 = ", merge_sort([-7, -1, 9, 40, 5, 6, 10, 11]))
print("정답 = [-1, 2, 3, 5, 10, 40, 78, 100] / 현재 풀이 값 = ", merge_sort([-1, 2, 3, 5, 40, 10, 78, 100]))
print("정답 = [-1, -1, 0, 1, 6, 9, 10] / 현재 풀이 값 = ", merge_sort([-1, -1, 0, 1, 6, 9, 10]))
스택(stack)
스택은 데이터를 임시 저장할 때 사용하는 자료구조로, 데이터의 입력과 출력 순서는 후입선출 FILO(first in last out) 방식이다. 데이터를 제한적으로 접근할 수 있는 구조이고, 한쪽 끝에서만 자료를 넣거나 뺄 수 있는 구조이다.
스택은 콜 스택(call stack)이라 하여 컴퓨터 프로그램의 서브루틴에 대한 정보를 저장하는 자료구조에도 널리 활용된다. 컴파일러가 출력하는 에러도 스택처럼 맨 마지막 에러가 가장 먼저 출력되는 순서를 보인다. 또한 스택은 메모리 영역에서 LIFO(last in first out) 형태로 할당하고 접근하는 구조인 아키텍처 레벨의 하드웨어 스택의 이름으로도 널리 사용된다. 이외에도 꽉 찬 스택에 요소를 삽입하고자 할 때 스택에 요소가 넘쳐서 에러가 발생하는 것을 스택 버퍼 오버플로(stack buffer overflow)라고 부른다. 질의응답 서비스 사이트인 스택오버플로의 명칭도 여기서 유래했다.
스택은 거의 모든 애플리케이션을 만들 때 사용되는 자료구조로서, 스택과 연관된 알고리즘을 제대로 이해하느냐 못하느냐에 따라 기본 알고리즘을 설계할 수 있느냐 없느냐가 결정되기도 한다.
- 스택의 기능
push(data) : 맨 앞에 데이터 넣기
pop() : 맨 앞의 데이터 뽑기
peek() : 맨 앞의 데이터 보기
isEmpty() : 스택이 비었는지 안 비었는지 여부 반환해주기
- 스택의 장단점
장점
- 구조가 단순해서 구현이 쉽다.
- 데이터 저장/읽기 속도가 빠르다.
단점(일반적인 스택 구현 시)
- 데이터 최대 갯수를 미리 정해야 한다. -> 파이썬의 겨우 재귀 함수는 1000번까지만 호출이 가능함
- 저장 공간의 낭비가 발생할 수 있다. -> 미리 최대 갯수만큼 저장 공간 확보해야 함
스택의 경우 단순하고 빠른 성능을 위해 사용되므로, 보통 배열 구조를 활용해서 구현하는 것이 일반적이다. 이경우, 위에서 열거한 단점이 있을 수 있다.
- 스택 구현하기
class Node:
def __init__(self, data):
self.data = data
self.next = None
class Stack:
def __init__(self):
self.head = None
def push(self, value):
new_head = Node(value)
new_head.next = self.head
self.head = new_head
# pop 기능 구현
def pop(self):
if self.is_empty():
return "Stack is Empty"
delete_head = self.head
self.head = self.head.next
return delete_head.data
def peek(self):
if self.is_empty():
return "Stack is Empty"
return self.head.data
# isEmpty 기능 구현
def is_empty(self):
return self.head is None
stack = Stack()
stack.push(3)
print(stack.peek())
stack.push(4)
print(stack.peek())
print(stack.pop())
- 스택 예제
top_heights = [6, 9, 5, 7, 4]
def get_receiver_top_orders(heights):
answer = [0] * len(heights)
while heights:
height = heights.pop()
for idx in range(len(heights) - 1, -1, -1):
if heights[idx] > height:
answer[len(heights)] = idx + 1
break
return answer
print(get_receiver_top_orders(top_heights)) # [0, 0, 2, 2, 4] 가 반환되어야 한다!
print("정답 = [0, 0, 2, 2, 4] / 현재 풀이 값 = ",get_receiver_top_orders([6,9,5,7,4]))
print("정답 = [0, 0, 0, 3, 3, 3, 6] / 현재 풀이 값 = ",get_receiver_top_orders([3,9,9,3,5,7,2]))
print("정답 = [0, 0, 2, 0, 0, 5, 6] / 현재 풀이 값 = ",get_receiver_top_orders([1,5,3,6,7,6,5]))
큐(Queue)
스택과 같이 데이터를 임시 저장하는 자료구조이다. 하지만 스택처럼 가장 나중에 넣은 데이터를 가장 먼저 꺼내지 않는다. 가장 먼저 넣은 데이터를 가장 먼저 꺼내는 선입선출 FIFO(first in first out) 구조이다. 멀티 태스킹을 위한 프로세스 스케줄링 방식을 구현하기 위해 많이 사용된다.
- 큐의 기능
enqueue(data) : 맨 뒤에 데이터 추가하기
dequeue() : 맨 앞의 데이터 뽑기
peek() : 맨 앞의 데이터 보기
isEmpty() : 큐가 비었는지 안 비었는지 여부 반환해주기
파이썬 queue 라이브러리
- Queue(), LifoQueue(), PriorityQueue() 제공
- Queue(): 가장 일반적인 큐 자료구조
- LifoQueue(): 나중에 입력된 데이터가 먼저 출력되는 구조(like 스택)
- PriorityQueue(): 데이터마다 우선순위를 넣어서, 우선순위가 높은 순으로 데이터 출력
- 큐 구현하기
class Node:
def __init__(self, data):
self.data = data
self.next = None
class Queue:
def __init__(self):
self.head = None
self.tail = None
def enqueue(self, value):
new_node = Node(value)
if self.is_empty():
self.head = new_node
self.tail = new_node
return
self.tail.next = new_node
self.tail = new_node
def dequeue(self):
if self.is_empty():
return "Queue is Empty"
delete_head = self.head
self.head = self.head.next
return delete_head.data
def peek(self):
if self.is_empty():
return "Queue is Empty"
return self.head.data
def is_empty(self):
return self.head is None
queue = Queue()
queue.enqueue(3)
print(queue.peek())
queue.enqueue(4)
print(queue.peek())
print(queue.dequeue())
해쉬
컴퓨팅에서 키를 값에 매핑할 수 있는 구조인, 연관 배열 추가에 사용되는 자료 구조이다. 해시 테이블은 해시 함수를 사용하여 색인(index)을 버킷(bucket)이나 슬롯(slot)의 배열로 계산한다. 데이터를 다루는 기법 중에 하나로 데이터의 검색과 저장이 아주 빠르게 진행된다.
딕셔너리를 해쉬 테이블이라고 부르기도 한다.
- 딕셔너리 구현하기
class Dict:
def __init__(self):
self.items = [None] * 8
def put(self, key, value):
index = hash(key) % len(self.items)
self.items[index] = value
return
def get(self, key):
index = hash(key) % len(self.items)
return self.items[index]
my_dict = Dict()
my_dict.put("test", 3)
print(my_dict.get("test")) # 3이 반환되어야 합니다!해쉬 충돌
해쉬의 값이 같게 되면 같은 어레이의 인덱스로 매핑이 되어서 데이터를 덮어 써버리는 결과가 발생한다.
이를 충돌(collision)이 발생했다고 한다.
충돌 해결방법
- 체이닝(Chaining)
class LinkedTuple:
def __init__(self):
self.items = list()
def add(self, key, value):
self.items.append((key, value))
def get(self, key):
for k, v in self.items:
if key == k:
return v
class LinkedDict:
def __init__(self):
self.items = []
for i in range(8):
self.items.append(LinkedTuple())
def put(self, key, value):
index = hash(key) % len(self.items)
self.items[index].add(key, value)
def get(self, key):
index = hash(key) % len(self.items)
return self.items[index].get(key)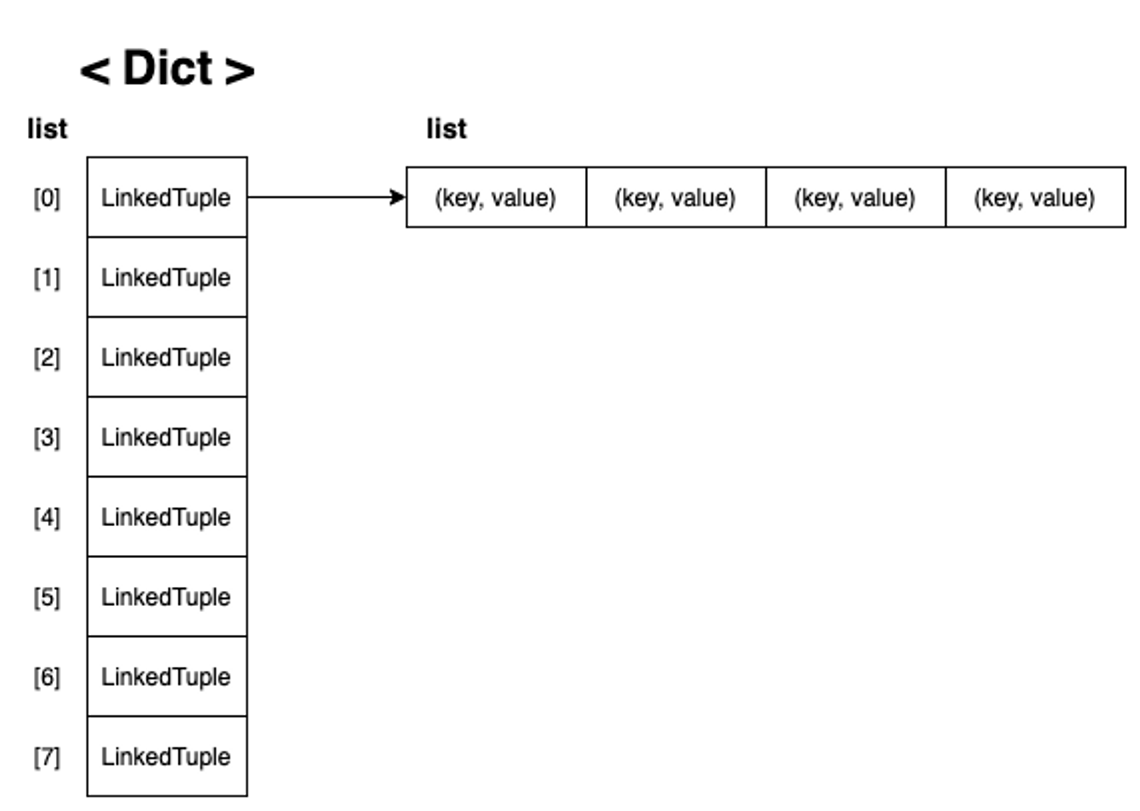
- 개방 주소법(Open Addressing)
선형 조사법에서는 만약 충돌이 ht[k]에서 충돌이 발생했다면 ht[k+1], ht[k+2], ht[k+3]...이 비어 있는지를 살펴본다. 이런 식으로 비어있는 공간이 나올 때까지 계속하여 조사하는 방법이다.
- 해쉬 예제
all_students = ["나연", "정연", "모모", "사나", "지효", "미나", "다현", "채영", "쯔위"]
present_students = ["정연", "모모", "채영", "쯔위", "사나", "나연", "미나", "다현"]
def get_absent_student(all_array, present_array):
dict = {}
for key in all_array:
dict[key] = True # 아무 값이나 넣어도 상관 없습니다! 여기서는 키가 중요한거니까요
for key in present_array: # dict에서 key 를 하나씩 없앱니다
del dict[key]
for key in dict.keys(): # key 중에 하나를 바로 반환합니다! 한 명 밖에 없으니 이렇게 해도 괜찮습니다.
return key
print(get_absent_student(all_students, present_students))
print("정답 = 예지 / 현재 풀이 값 = ",get_absent_student(["류진","예지","채령","리아","유나"],["리아","류진","채령","유나"]))
print("정답 = RM / 현재 풀이 값 = ",get_absent_student(["정국","진","뷔","슈가","지민","RM"],["뷔","정국","지민","진","슈가"]))
3주차 숙제
- 최대로 할인 적용하기
shop_prices = [30000, 2000, 1500000]
user_coupons = [20, 40]
def get_max_discounted_price(prices, coupons):
coupons.sort(reverse=True)
prices.sort(reverse=True)
price_index = 0
coupon_index = 0
max_discounted_price = 0
while price_index < len(prices) and coupon_index < len(coupons):
max_discounted_price += prices[price_index] * (100 - coupons[coupon_index]) / 100
price_index += 1
coupon_index += 1
while price_index < len(prices):
max_discounted_price += prices[price_index]
price_index += 1
return round(max_discounted_price)
print("정답 = 926000 / 현재 풀이 값 = ", get_max_discounted_price([30000, 2000, 1500000], [20, 40]))
print("정답 = 485000 / 현재 풀이 값 = ", get_max_discounted_price([50000, 1500000], [10, 70, 30, 20]))
print("정답 = 1550000 / 현재 풀이 값 = ", get_max_discounted_price([50000, 1500000], []))
print("정답 = 1458000 / 현재 풀이 값 = ", get_max_discounted_price([20000, 100000, 1500000], [10, 10, 10]))
- 올바른 괄호
def is_correct_parenthesis(string):
stack = []
for i in range(len(string)):
if string[i] == "(":
stack.append(i) # 여기 아무런 값이 들어가도 상관없습니다! ( 가 들어가있는지 여부만 저장해둔 거니까요
elif string[i] == ")":
if len(stack) == 0:
return False
stack.pop()
if len(stack) != 0:
return False
else:
return True
print("정답 = True / 현재 풀이 값 = ", is_correct_parenthesis("(())"))
print("정답 = False / 현재 풀이 값 = ", is_correct_parenthesis(")"))
print("정답 = False / 현재 풀이 값 = ", is_correct_parenthesis("((())))"))
print("정답 = False / 현재 풀이 값 = ", is_correct_parenthesis("())()"))
print("정답 = False / 현재 풀이 값 = ", is_correct_parenthesis("((())"))
- 베스트 앨범 뽑기
def get_melon_best_album(genre_array, play_array):
n = len(genre_array)
genre_total_play_dict = {}
genre_index_play_array_dict = {}
for i in range(n):
genre = genre_array[i]
play = play_array[i]
if genre not in genre_total_play_dict:
genre_total_play_dict[genre] = play
genre_index_play_array_dict[genre] = [[i, play]]
else:
genre_total_play_dict[genre] += play
genre_index_play_array_dict[genre].append([i, play])
sorted_genre_play_array = sorted(genre_total_play_dict.items(), key=lambda item: item[1], reverse=True)
result = []
for genre, _value in sorted_genre_play_array:
index_play_array = genre_index_play_array_dict[genre]
sorted_by_play_and_index_play_index_array = sorted(index_play_array, key=lambda item: item[1], reverse=True)
for i in range(len(sorted_by_play_and_index_play_index_array)):
if i > 1:
break
result.append(sorted_by_play_and_index_play_index_array[i][0])
return result
print("정답 = [4, 1, 3, 0] / 현재 풀이 값 = ", get_melon_best_album(["classic", "pop", "classic", "classic", "pop"], [500, 600, 150, 800, 2500]))
print("정답 = [0, 6, 5, 2, 4, 1] / 현재 풀이 값 = ", get_melon_best_album(["hiphop", "classic", "pop", "classic", "classic", "pop", "hiphop"], [2000, 500, 600, 150, 800, 2500, 2000]))